
System Design is Broken :\
No it is perhaps not. We are engineers. We build systems, we try to stay sane doing it but how does the design of deterministic systems evolve for non deterministic ones?

I was sketching out an architecture on a whiteboard the other day. It seemed clean.
A classic setup: microservices, a message queue for async tasks, a caching layer for performance, a robust relational database for our source of truth. Boxes and lines, all neat and tidy. We, as engineers, have spent decades perfecting this dance of deterministic components. We know the steps.
Then, I drew one more arrow. An arrow pointing from one of our core services to a box I labelled "LLM Backend." And I had to stop.
The entire diagram, all that hard-won certainty, suddenly felt like a lie.
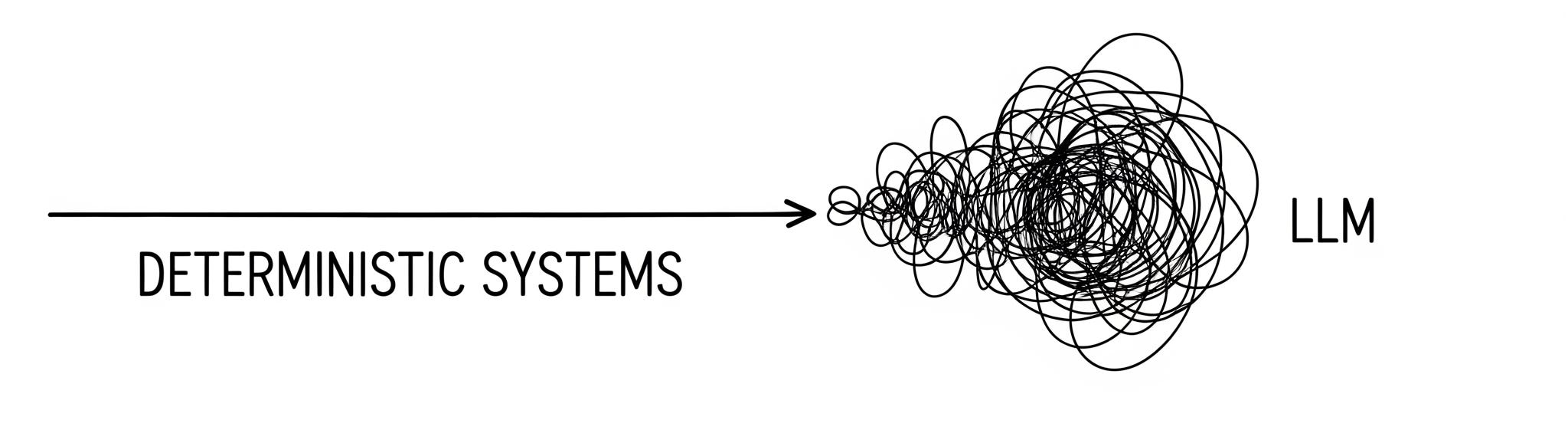
In this blog, I want to talk about something that keeps me up at night. I want to talk about the moment after the LLM has done its magic. The moment its response which is a stream of tokens holding immense promise and subtle chaos hits your system.
Because at that single point of contact, our most trusted principles of system design begin to fracture.
Let's be honest with ourselves. The patterns that gave us scale, reliability, and sanity for the last many years are being fundamentally challenged by this new, non-deterministic beast we’ve invited into the heart of our systems.
The Anomaly: The Brilliant, Unreliable ‘Thing’ -
The core of the problem is this: an LLM is not just another API. A call to the Stripe API is a transaction. A call to the Twilio API is an instruction. They are deterministic. You get a predictable success, a predictable failure. You can build contracts around that.
A call to an LLM is a conversation with a brilliant, unpredictable, and slightly unhinged “thing”.
You can ask it to generate a user profile summary, and it might return a perfectly structured JSON object. The schema is valid, the data types are correct.
But the user’s location might be subtly wrong. The summary might capture the tone but hallucinate a key skill.
It’s not a 500 Internal Server Error. It’s not a 400 Bad Request. It’s a 200 OK that lies.
And that is infinitely more terrifying.
This single property - The ability to be formally correct but semantically wrong is the wrecking ball that’s about to crash through our foundational patterns.
Think about all the fancy words we throw around in system design interviews. Let's see how they hold up.
Reliability: From Uptime to Trust
For years, reliability meant our service was up and responding. We measured it with SLOs, uptime percentages, and error rates. If the service returned a 200, the reliability box was ticked.
That definition is now dangerously insufficient.
The new reliability is about semantic trust. Can you trust what the LLM says?
If your e-commerce site uses an LLM to generate product descriptions, what happens when it confidently hallucinates a feature the product doesn’t have? The service didn't go down. The error rate is zero. But you just broke a promise to your customer.
Our systems now need a "reliability" layer that sits on top of the transport layer. We have to start thinking about validation layers, fact-checking against a ground truth, and maybe even using a second, more powerful "referee" LLM to score the first one's response. Reliability is no longer a binary state; it’s a probabilistic score.
Idempotency: The End of Predictable Retries
Idempotency has been our safety net. A user clicks "Submit" twice? No problem, the POST /resource call is idempotent. A network blip causes a retry? The queue worker can safely re-process the message. f(x) always equals f(x).
Now, try that with an LLM. Ask it to /summarize_article twice with temperature > 0. You will get two different summaries. They might be subtly different or wildly different.
What does this mean for our patterns? Caching a response is now a strategic choice with a trade-off, not a default performance win. Do you cache the first response and lose out on potentially better ones? Do you call it every time and pay the latency and monetary cost? Retrying a failed downstream process that depends on an LLM’s output is no longer simple. You can't just replay the request, because the LLM's response, the very input for that downstream process might change.
Scalability: The New Bottleneck is Probabilistic
We know how to scale stateless services. Add more nodes. Easy. But you can't just spin up more instances of Sonnet-4 on your own cluster. The primary bottleneck is now a third-party, opaque service with high and, more importantly, variable latency.
Generating a simple response might take 500ms. A complex one might take 30 seconds.
This shifts the scalability problem from raw throughput to perceived performance and managing concurrency.
Our architectures now need to be built for streaming by default.
We can’t have a user staring at a spinner for 30 seconds. We need to design systems that can handle partial, streamed responses, painting the UI as the tokens arrive.
The engineering challenge has moved from scaling servers to managing user psychology.
Consistency & The CAP Theorem: A New Kind of Split-Brain
We obsess over consistency models. Eventual consistency, strong consistency. The CAP theorem tells us we must choose between Consistency, Availability, and Partition Tolerance in our distributed data stores.
But what happens when one of your "nodes" is an LLM with a knowledge cutoff of last year?
You now have a new, terrifying consistency problem: the consistency between your application's ground truth (your product database, your user data) and the LLM's vast but stale and generalized worldview. The LLM can generate advice that directly contradicts your own system's state. It can reference features you’ve deprecated. It can be confidently unaware of your new product line.
This is a split-brain scenario not between data centers, but between your system and its AI-powered extension.
The new consistency problem isn't between your replicas. It’s between your database and your AI’s delusion.
One way to ensure consistency is to never let the LLM operate in a vacuum. Every single call must be "grounded" with real-time, relevant context.
So, What Do We Do? The New Engineering Disciplines
This all sounds gloomy, but it's not. It's a new frontier, and new frontiers require new tools and new thinking.
The challenge for our generation of engineers is to build the patterns that tame this chaos.
But How?
Well, I am not expert but I have some opinions.
First, we have to re-think Testability. assert response == "expected_output" is dead. Our testing pyramid needs new layers:
Structural Tests: Don't check the content, check the container. Is it valid JSON? Does it adhere to the Pydantic or Zod schema I demanded?
Semantic & Quality Tests: This is harder. It might involve using a more powerful LLM (like Sonnet-4) in your CI/CD pipeline as a "referee" to evaluate the output of your cheaper, faster production model (like a fine-tuned Llama). You ask it, "Does this response accurately summarize the source text? Rate from 1 to 10." There can be multiple ways including evals but you get the gist.
Behavioral & Guardrail Tests: Test for what it shouldn't do. Does it refuse to answer harmful questions? Does it correctly identify when a query is out-of-scope?
Second, we must redefine Observability. The classic three pillars (logs, metrics, traces) are no longer enough. A 200 OK trace is a meaningless vanity metric if the response was a lie. We need to new pillars:
Semantic Correctness & Hallucination Tracking: We must log not just the response, but signals about its quality. Did a validation function flag it as potentially incorrect? Did it contradict our ground-truth database?
Cost & Token Tracking: Every LLM call has a real, direct cost in rupees or dollars. This has to be a first-class metric tied to every trace and transaction.
Human in the Loops: That "thumbs up/down" button on the UI is no longer a nice-to-have. It’s a critical observability signal that must be fed directly back into your monitoring dashboards. It’s the ultimate measure of semantic reliability.
System design isn't dead. But it is changing.
The deterministic certainty of algorithmic logic is giving way to the probabilistic nature of neural networks. T
The clean lines on our whiteboards now need to have fuzzy edges, error bars, and confidence scores.
Our job is no longer just to build systems that are fast, scalable, and available. Our job is to build systems that are wise, robust, and trustworthy in the face of a powerful, creative, and fundamentally chaotic new partner. And honestly? I can’t think of a more interesting problem to solve.
Need to unengineer a lot to be able to unengineer a lot more! (I love that I named my blog “unengineered”)
so many great points, but my fav one is "The engineering challenge has moved from scaling servers to managing user psychology."