Let's face it, GenAI has undeniably become the tech darling of the 2020s. All tech leaders and CTOs are perhaps thinking more about it than anything else. VCs are bullish on new AI startups. Middle managers in engineering and product teams are suddenly looking for more ownership. While some in tech feel the crisis of it, there also are kick ass teams and people who are embracing it and going all out while building amazing stuff with Generative AI.
Thanks for reading Unengineered! Subscribe for free to receive new posts and support my work.
But here’s the catch—taking those flashy GenAI demos to production isn’t quite as easy. The keynote demos we all admire? They’re designed to impress, not necessarily built to handle the intricacies of real-world use cases.
In production, things get real. That dream AI demo you saw in the conference keynote? It’s going to hallucinate. Those so perfect demo capabilities? Full of edge cases you didn't see coming.
It is less of a PPT with a premise, a promise and sellable marketing and more of a - this edge case, that hallucination and a questionable gurantee that your generative AI product will work as well generally for all use cases it promises to solve on production.
This is the first of a series of blogs on practical generative AI. This blog talks about first substantial steps engineering teams typically take in this landscape. It tries to tell the journey from the first use case to prod readiness and everything in between. This blog will focus on how teams can get it right, starting with common early implementations like chatbots and moving into the world of Retrieval-Augmented Generation (RAG)—the secret weapon of production-grade GenAI.
More blogs that follow in this series will touch upon how this journey further evolves.
Hype, Hope, and Hallucinations
This age of AI excites, promises and sometimes it threatens. Everyone's trying to jump on this bandwagon, but who's actually nailing it? And more importantly, how so ?
Leading giants in this space like Google, Microsoft, and OpenAI had already set the pace, integrating generative AI into mainstream applications with varying degrees of success.
OpenAI pushes towards more towards research, perhaps trying to evolve fundamenal language models, architecture and thought leadership which might set the space for AGI while Microsoft’s integration of AI into Office products and offering AI capabilities on Azure is an enterprise heavy business.
From where I see, Google’s seems to be playing a mixed game of research and direct to user use cases with some fresh attempts at new AI use cases every four weeks.
With Apple entering the race, this space in itself becomes more exciting.
But I am not writing this blog to talk about these “tech-giants” and their stories with AI. Their smallest of successes and failures become headlines and start trending the next day on twitter and take up all of our reddit timelines. [ :YAWN: ].
For the sake of it, let's clarify: Generative AI isn’t just about producing fancy text or images on command. At least VCs have not invested >760 million U.S. dollarsfor GenAI startups in India (as of the first half of 2024) just for this.
At its core, it involves deep learning models capable of generating new content based on patterns learned from existing data—whether that’s creating text, images, code, or even music. It spans everything from text-based models like GPT (for generating natural language text), to DALL·E (for generating images), and even extends to multimodal models (gpt 4-o) that handle a mix of inputs.
But here's the kicker: these systems aren’t omniscient—they don’t “know” anything in the human sense. Instead, they predict patterns based on vast amounts of training data, which is why hallucinations happen. When not grounded in actual data, they make up answers with shocking confidence. This nuance is important to understand as we navigate the transition from the excitement of GenAI to the gritty details of building it for production.
This blog tries to focus on smaller teams and their affairs with Generative AI on production. In the last few months, I have been actively seeking such stories trying to get it right and this blog focusses more on “How” than “Who”.
How does it all start?
This journey often begins with a mix of strategic necessity, technological curiosity, and/or Fear of Missing Out. But it really begins with identifying practical applications that can deliver immediate value.
Everyone I know has seen an internal GenAI hackathon happening in their org in the past year and a half. Typically the thought leadership towards Generative AI solutions starts on the premise of inferential problems, internal and support-ops workflows but perhaps the first substantial thing teams usually pick in this space are Chatbots, more so Chatbots 2.0 with AI capabilities.
Chatbots: The Gateway Drug of GenAI
More often than not, the journey starts with chatbots. It's not hard to see why. They're visible, they're interactive, and when done right, they can significantly improve customer experience while reducing workload on human teams.
Among many goals, the primary one often is to respond to customer with the “most right” answer for any query that comes.
Chatbots are the perhaps the most deceptively complex entry point among applied generative AI use cases. I've seen this movie before, and let me tell you, it's got more plot twists than "Predestination”.
The first generation of chatbots (before generative AI was a thing) were typically rule-based, using simple pattern matching. Then came the era of intent-based chatbots, which used machine learning for intent classification and entity extraction. Frameworks like RASA among others were popular for such use cases.
And when it came to GenAI chatbots, these are less "Computer says no" and more "Let me compose a sonnet about your customer service inquiry."
Funny but you will find it hard to find a company running without some version of such a chatbot today.
When you think of building such chatbots, some of the primary things you would want to consider, early in this journey are -
This should be able to help the customer with it’s query.
The answers should be factually correct and time taken to reply to a customer’s query be reduced significantly.
Such chatbots should generate human-like responses and handle complex, multi-turn conversations. The hard question however is to find a solution that confines the boundaries of this chat bot to your domain and your custom knowledge.
For example - A query asking - “If eye surgery covered in my insurance policy” should be as per the user’s purchased plan. If you paste the query directly on ChatGPT, it will not have an answer to it, because it does not have your policy details.
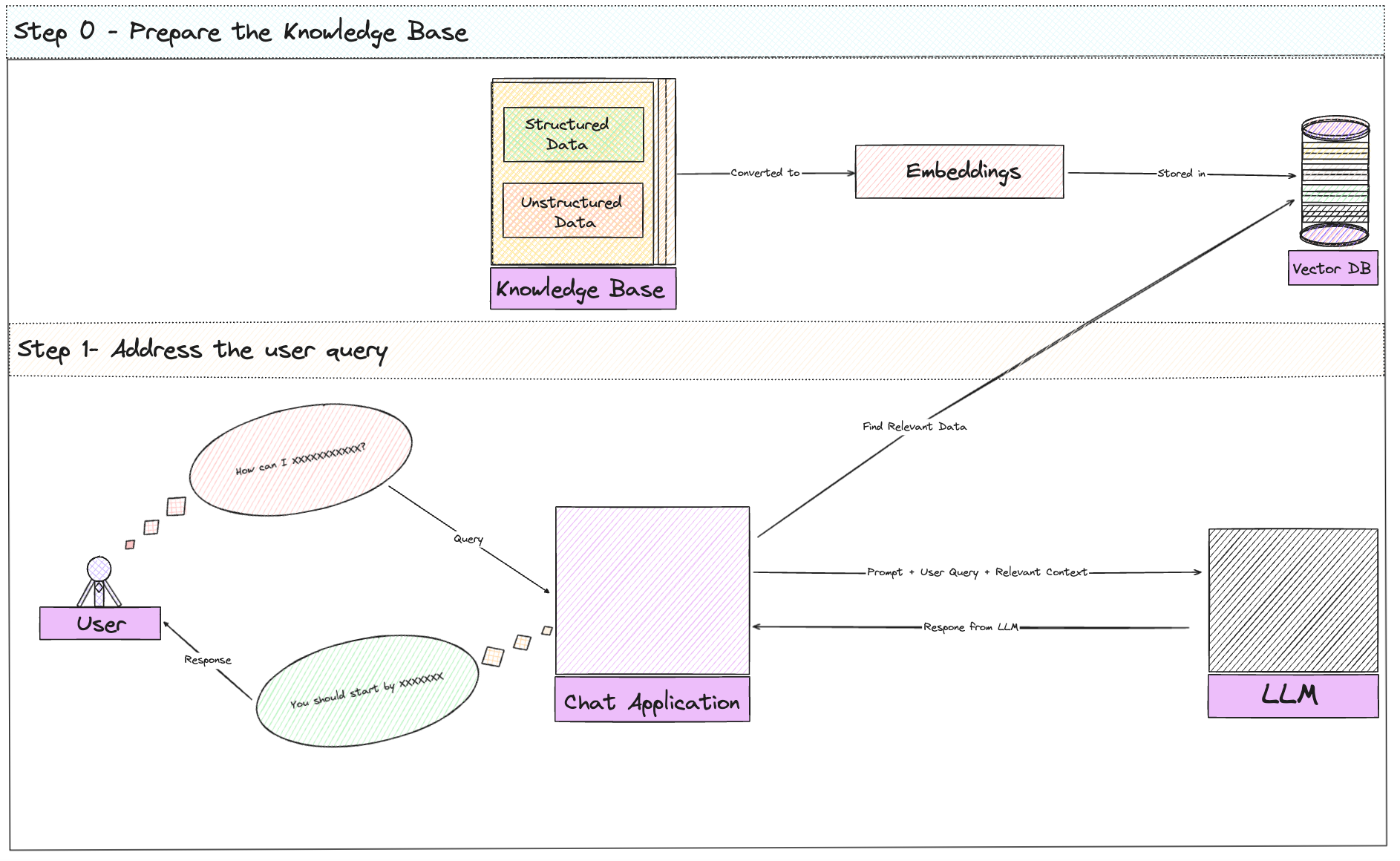
The secret sauce to get here is “RAG” - Retrieval Augmented Generation.
If you’ve worked with GenAI systems, you know the #1 problem isn’t generating text—GPT can do that in its sleep. The real challenge is grounding that generated text in factual, domain-specific knowledge. The teams which got early success on production and really nailed GenAI chatbots almost invariably used some form of RAG.
The RAG Advantage
RAG combines the strengths of retrieval-based and generative approaches. It allows the chatbot to ground its responses in specific, relevant information while maintaining the flexibility to generate new responses.
In its simplest form, RAG combines two approaches—retrieval-based and generative models.
Retrieval-based: This involves pulling relevant information from a knowledge base or document store. It’s like a search engine (on steroids)—finding the best snippets of information from a pile of data.
Generative-based: On the other hand, generative models (like Sonnet or GPT-4) can create new, human-like text on the fly. However, without grounding in real-world data, generative models are prone to “hallucinations,” where they generate confident but factually incorrect responses.
The genius of RAG is in combining these two techniques. By retrieving the most relevant pieces of information from your data store and then feeding that into a generative model, you get the best of both worlds: grounded, fact-based responses with a natural language flow.
Let’s break it down :
Problem: Language models like GPT-3.5 or GPT-4 are fantastic at generating coherent, human-like text. But they don’t inherently know your company's internal documentation, your product specifics, or the regulatory rules your industry follows. This leads to hallucinations—confident but incorrect outputs that can break trust in your product.
Solution: RAG solves this by retrieving relevant documents, knowledge, or data from a specific source (think your enterprise knowledge base, customer interaction logs, or product manuals) and augmenting the generative model’s input. This way, the AI isn’t just making stuff up; it’s constructing responses based on real-world, accurate data that you control.
Getting the RAG working
It’s an extreme fundamental of modern Generative AI to know, understand and implement RAG. It almost is not possible to solve a hard core ‘generative’ use case without suppling a domain specific context to LLM through RAG.
In a nutshell, to get working with RAG -
a. Take Your Data/Docs/Knowledge and Shred 'Em :)
Teams typically start by breaking down their knowledge base (FAQs, product manuals, etc.) into chunks, “n” tokens each.
b. Turn Data (Words, Images etc) into Math aka Embeddings:
These chunks are then converted into something called “vector embeddings”.
A vector embedding is simply a mathematical representation of data. Mathematical because math allows to perform calculations which later help with finding which data is similar to which, etc.
The embeddings are stored in a vector database. Popular choices include Pinecone, Weaviate, or FAISS.
These databases allow for fast similarity search, which is crucial for real-time performance.
c. Play the Matching Game
When a user query comes in, it's also converted to an vector embedding using the same model used for the documents.
The system then performs a similarity search (mathematical calculation) to find the most relevant document chunks.
d. Context Augmentation:
The retrieved chunks are used to augment the user's query, providing context for the language model. In simpler words, we take the best matches and use them to give our AI some context. It's like giving it a cheat sheet before the big test.
e. Let the AI Do Its Thing
The augmented query is then sent to a large language model (LLM) like GPT-3.5 or GPT-4.
The LLM generates a response based on prompt along with both the user's query and the retrieved context.
With the context we've given it, it can now generate a response that's actually relevant.
The first wave of GenAI-powered chatbots often fell flat on their faces because of one core issue: context. These early models were trained on massive corpora of text, but when deployed in real-world scenarios, they didn’t know how to handle domain-specific queries or long-tail edge cases. They could guess—but they often guessed wrong.
With Retrieval-Augmented Generation, the idea was simple: why make the AI guess when it could be informed? Why not give it real, relevant, domain-specific data so it can give better answers?
Choosing the right vector database for your RAG implementation isn’t just about going with the most popular name. There are significant trade-offs to consider. Pinecone, for instance, abstracts away the complexity of managing a large-scale vector search engine, making it ideal for teams that want a managed solution. However, if you're handling sensitive data or need to keep everything in-house for compliance reasons, FAISS offers more control, though at the cost of added operational overhead. With FAISS, you’re responsible for scaling, replication, and ensuring low-latency retrieval—tasks that aren’t trivial in production.
Moreover, search techniques matter. While cosine similarity is the go-to for most vector search tasks, some applications may benefit from k-nearest neighbors (KNN) or approximate nearest neighbor (ANN) algorithms for balancing speed and accuracy, especially when dealing with high-dimensional data.
When handling large datasets, sharding your vector database becomes crucial. The larger your dataset grows, the more likely you are to hit performance bottlenecks. A common approach is to shard embeddings across multiple nodes and run distributed similarity searches. This allows the system to scale horizontally and handle higher throughput without sacrificing performance.
The RAG Disadvantage
While the concept of RAG might sound like a silver bullet, implementing it in production has its own set of challenges.
Latency is a primary concern—retrieving the most relevant document chunks in real time can quickly become a bottleneck if your knowledge base is vast or frequently updated. Scaling becomes an issue, especially when you're working with vector databases that need to handle thousands of queries per second while maintaining fast similarity searches.
There’s also the matter of knowledge drift. Imagine a company’s product specs change frequently—your chatbot might still be retrieving old documents unless you're constantly retraining your embeddings and refreshing the vector database. Knowledge bases don’t remain static, and managing those updates without retraining from scratch is tricky. Solutions like continuous embedding refresh cycles or using hybrid retrieval models that blend keyword search with embeddings can help teams mitigate this.
Finally, even in RAG, there's the risk of retrieving conflicting or ambiguous information. A major practical challenge is resolving these conflicts or ensuring that only the most reliable documents are retrieved in ambiguous scenarios. Techniques like re-ranking retrieved documents based on confidence scores, recency, or relevance can help resolve this tension.
What happens when RAG gets it wrong?
Whether it's because your vector database failed to retrieve relevant documents, or the generative model misunderstood the user query, error handling becomes paramount.
One common strategy is implementing fallback mechanisms. When retrieval fails or no relevant documents are found, your system could revert to simpler, rule-based responses or rely on a backup FAQ system. This approach ensures that the chatbot doesn’t stall out or return nonsensical answers when the RAG system fails. Another common pattern is multi-pass retrieval, where the system first attempts to retrieve documents from a specialized dataset and, if that fails, expands the search to a broader data pool.
In high-traffic environments, it's essential to monitor response latency and implement circuit breakers for when the system is overloaded. When response times start exceeding acceptable thresholds, circuit breakers can degrade gracefully by switching to pre-defined responses instead of dynamic generation.
Breaking Down the Engineering that goes behind
Building a Retrieval-Augmented Generation (RAG) powered AI chatbot isn’t just about plugging APIs into each other and calling it a day.
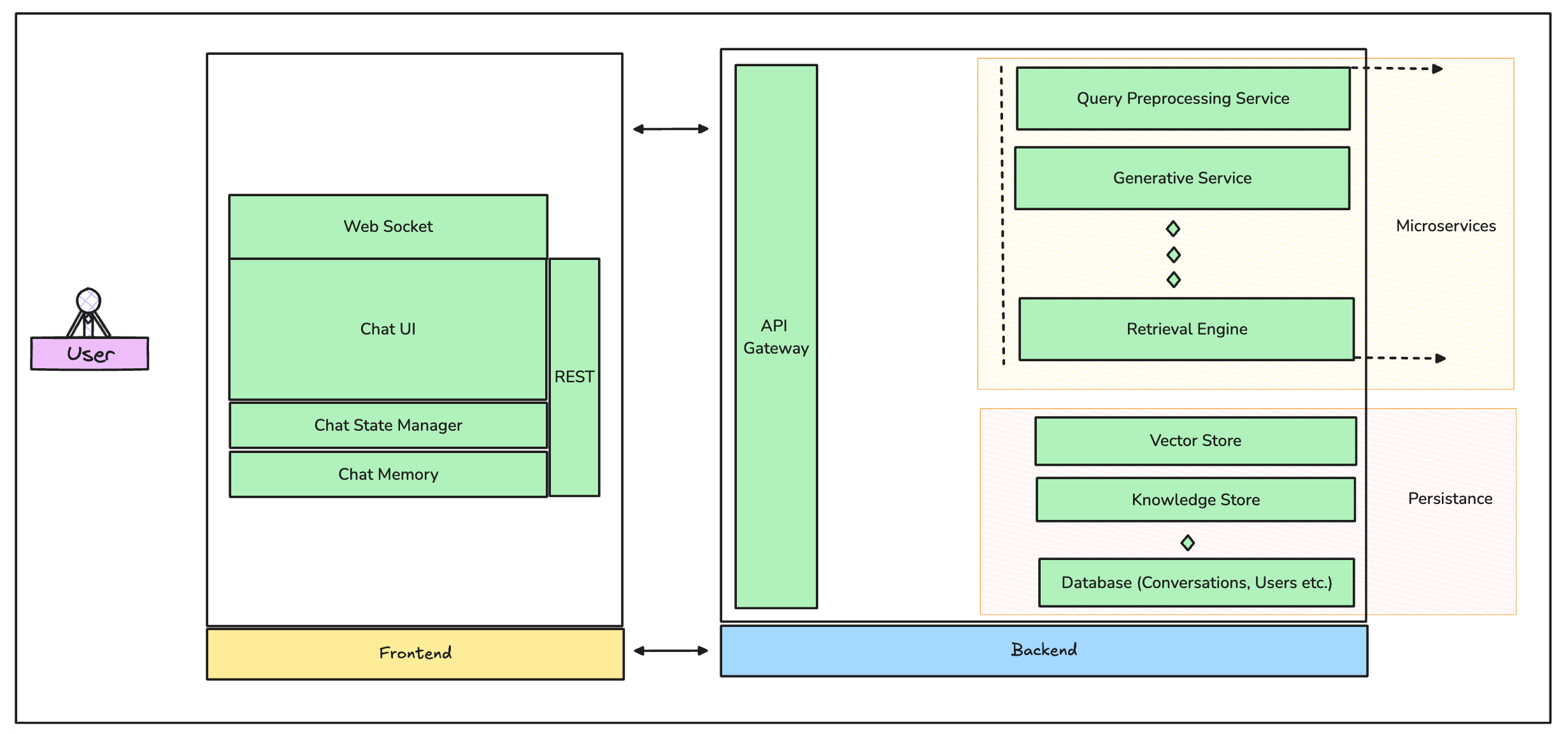
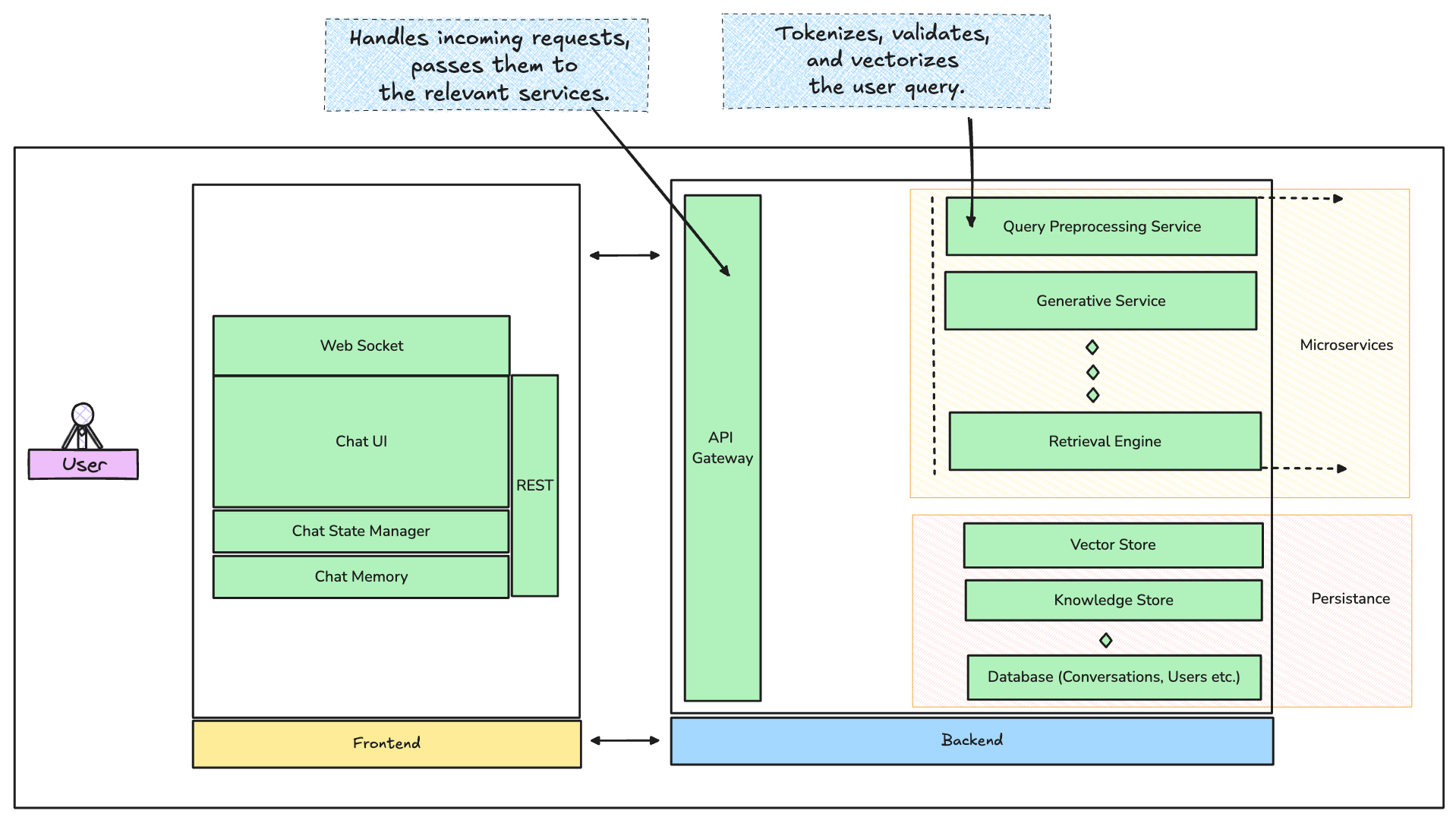
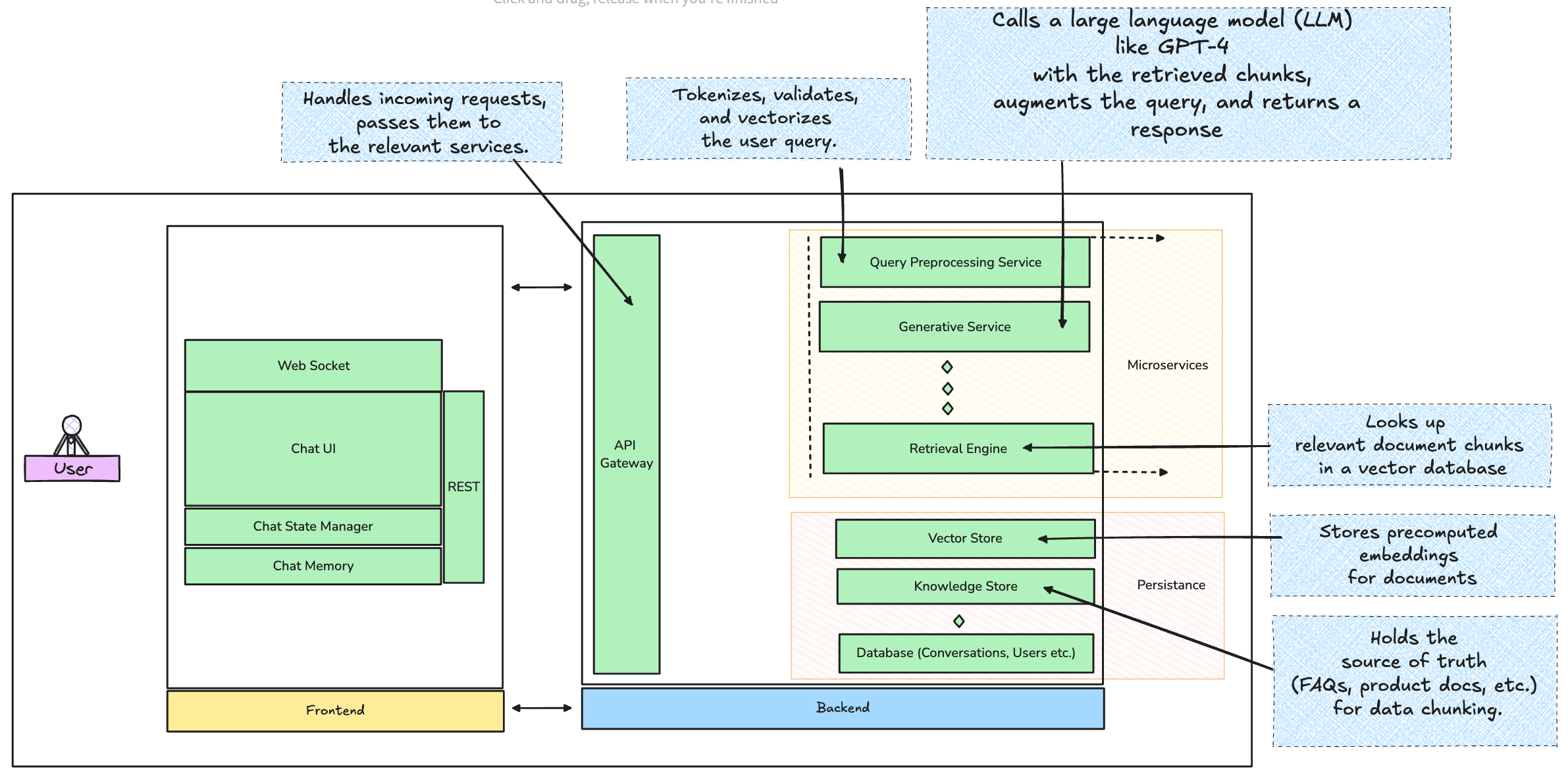
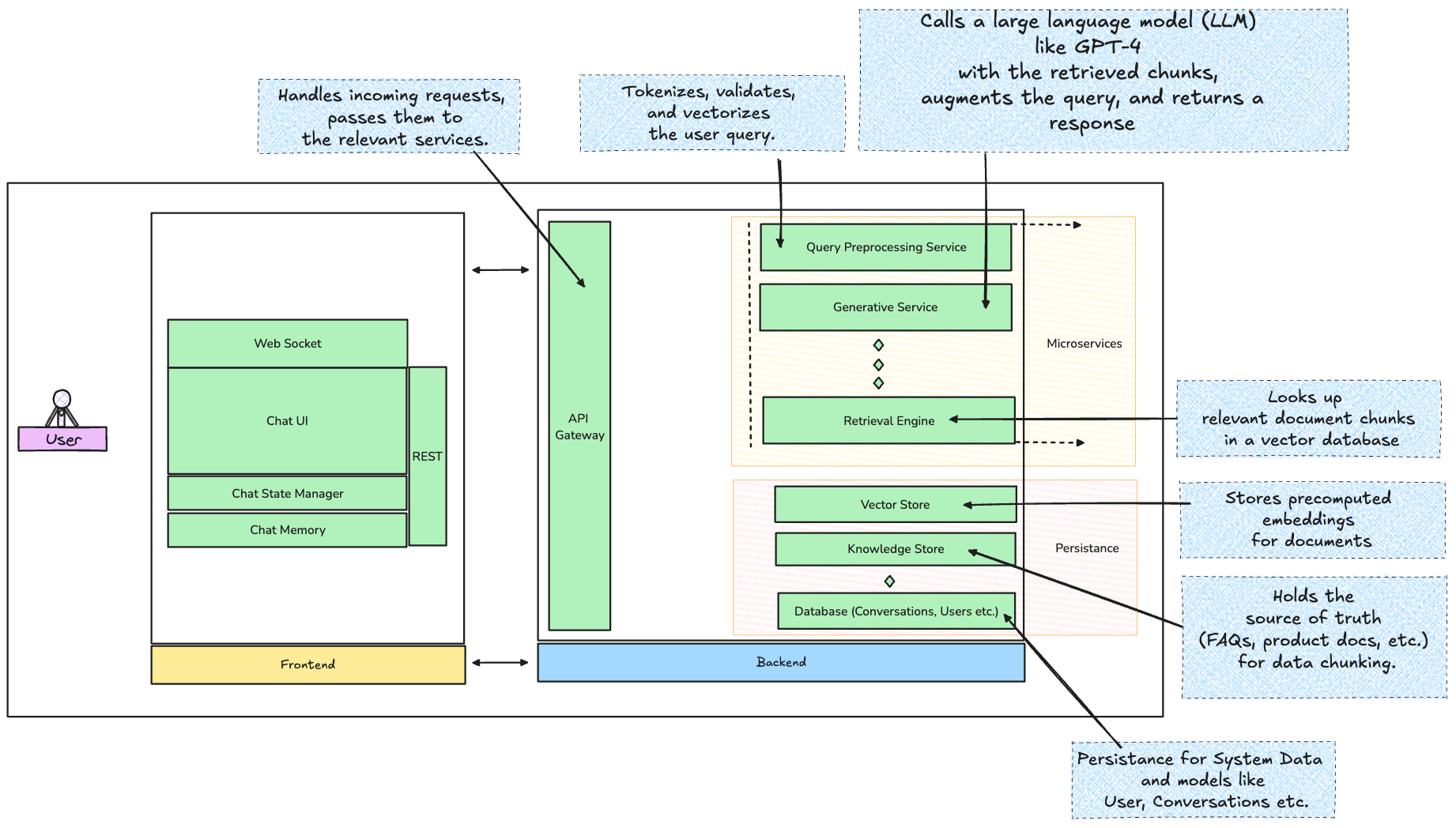
First off, let’s paint the big picture. What you’re building here is essentially some version of a distributed system, where real-time query handling, document retrieval, and generative responses need to happen seamlessly across multiple layers. The architecture should handle bursts of traffic, handle fault tolerance, and respond fast enough to meet user expectations.
The system might look something like the graphic above.
Let’s break it down a little:
The Backend
This is where the magic happens. No backend, no wizardry.
The backend of a RAG-powered chatbot is the part that processes the user’s query, finds relevant information faster than you can say “asynchronous I/O,” and generates responses that feel human (minus the existential dread)
The backend is where your chatbot’s intelligence lives. It’s also where efficiency is either won or lost, so design choices here need to strike a balance between accuracy, latency, and scalability. Let’s dissect the components.
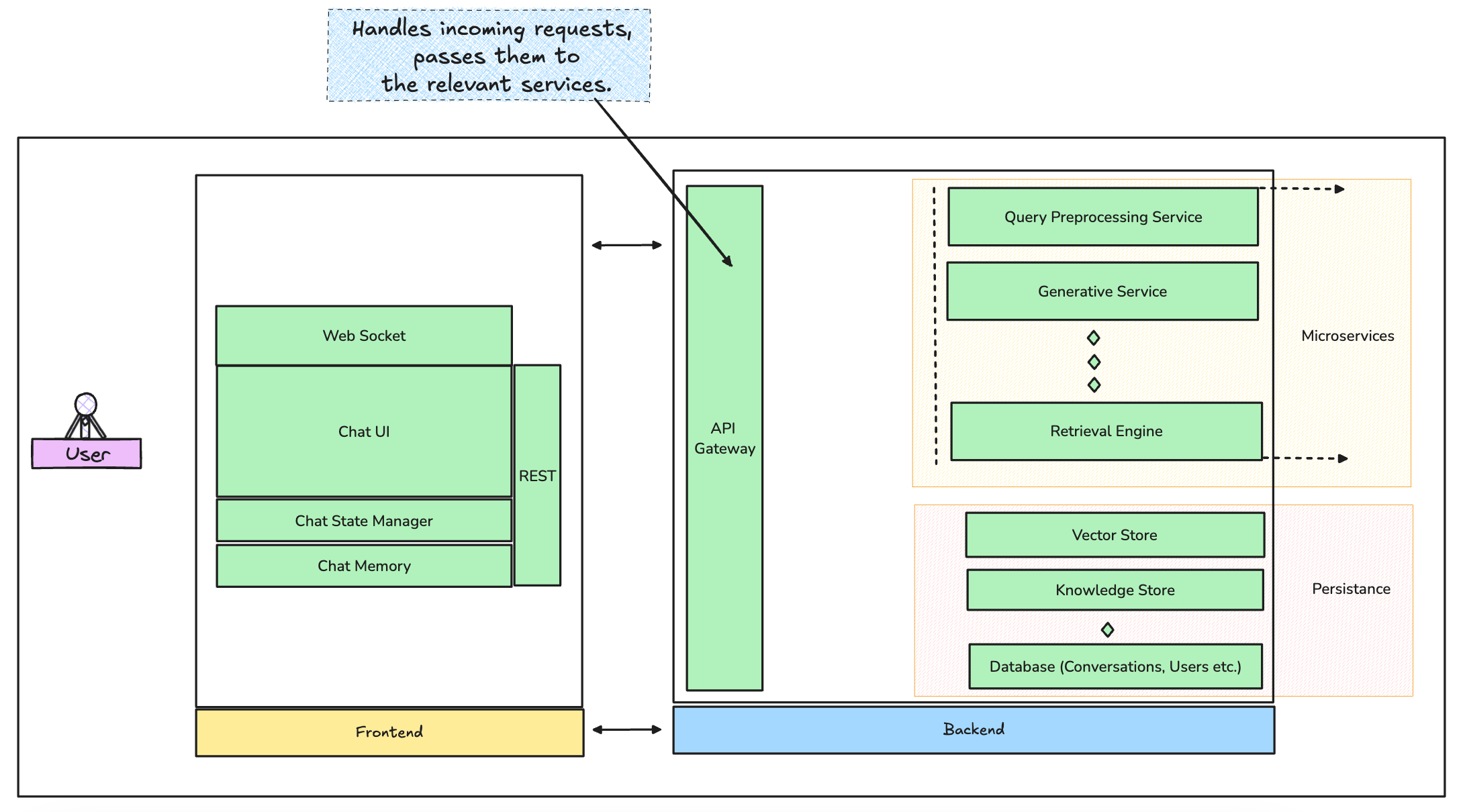
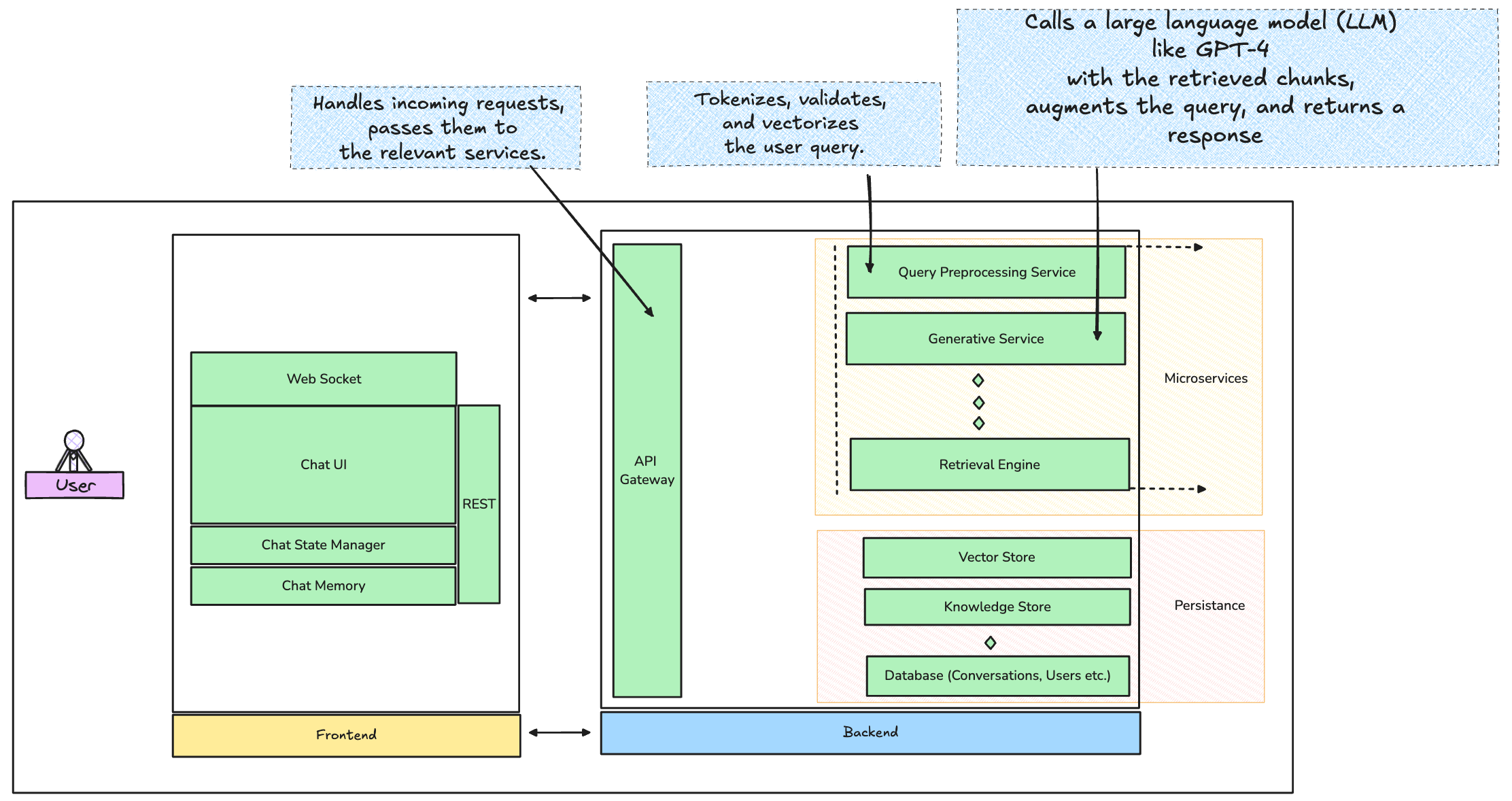
1. API Gateway
This is the entry point for all user requests handling routing, authentication, and rate limiting among other things.
Authentication/Rate Limiting: Since LLM calls are costly, you need tight control over the volume of incoming queries. Add an API key layer and ensure rate limiting is baked in to prevent misuse.
Once the query hits the backend, it first needs preprocessing. This includes:
Tokenization: Breaking the query into manageable chunks.
Validation: Ensuring the query doesn’t contain malicious content (use Sanic or FastAPI middleware for this).
Vectorization: Convert the query into an embedding. This is where your choice of pre-trained embedding models comes in—BERT or OpenAI’s embedding API could be your go-to.
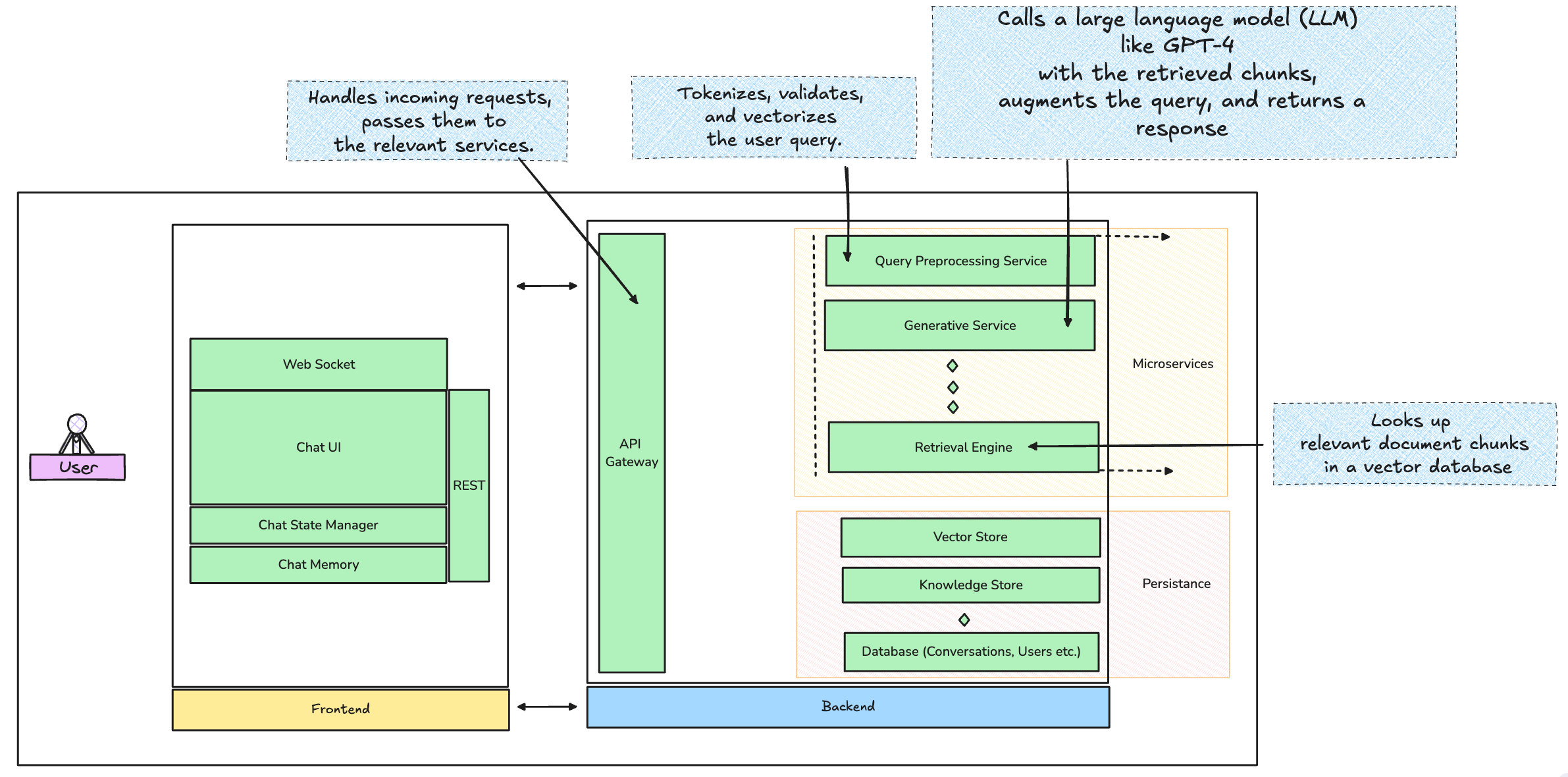
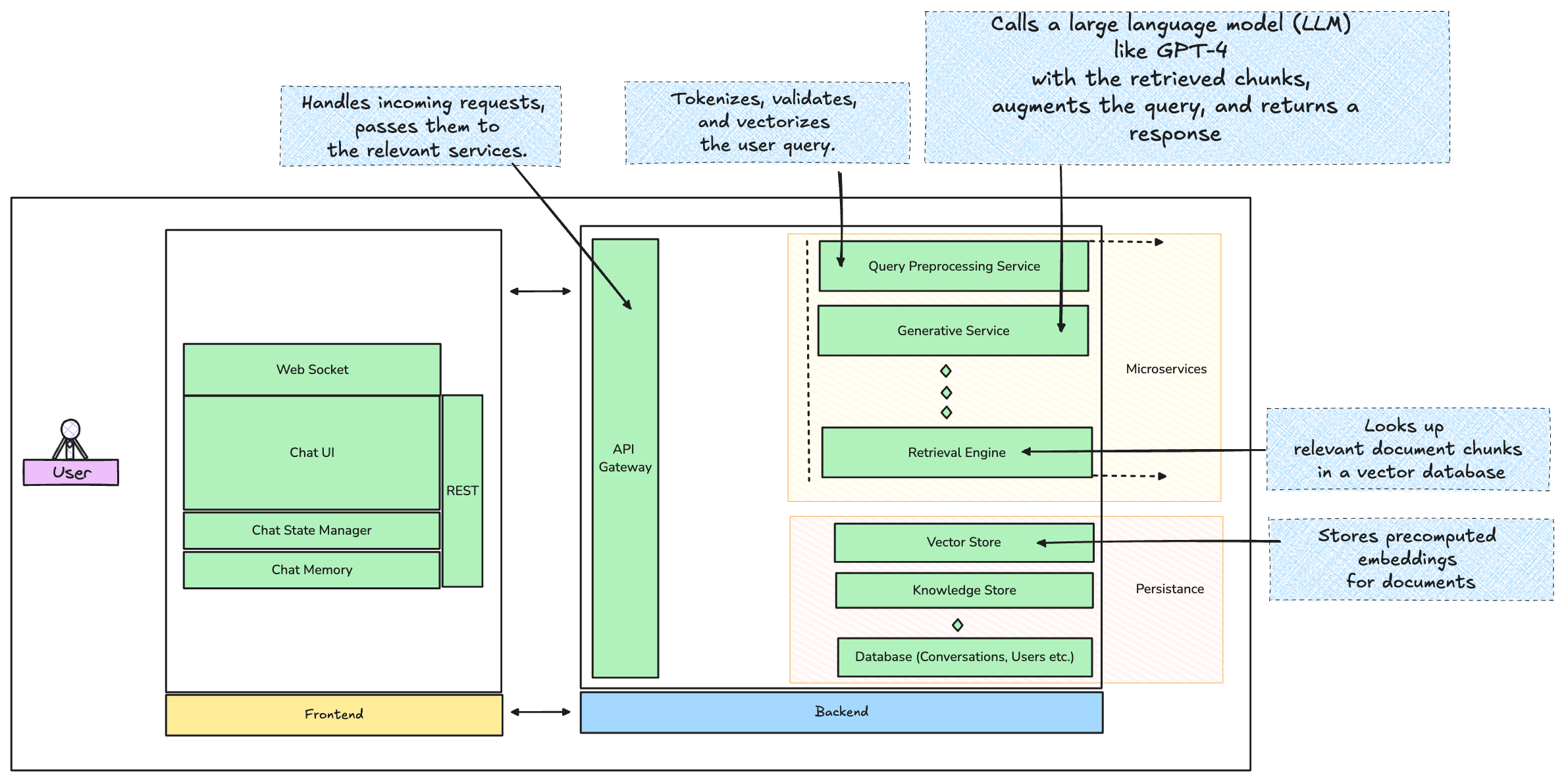
3. Retrieval Engine
The retrieval engine is the powerhouse for pulling relevant data. This is where RAG truly shines, augmenting the chatbot’s capabilities.
Vector Database: Store your preprocessed document chunks as vectors. Best options here? Pinecone for managed hosting or FAISS for self-hosted deployments. Pinecone abstracts all the complexity of managing your vector database and scales beautifully, while FAISS gives you more control if you need to keep everything in-house.
Similarity Search: The vectorized query is sent to the database, where a similarity search pulls back the top N most relevant document chunks. Cosine similarity or KNN search methods are typically used for this.
Pro Tip: To improve response times, pre-warm your vector database. Don’t wait until your user sends a query to load relevant embeddings. Keep commonly requested queries in memory with smart caching, and use Redis for storing frequently accessed embeddings.
4. Generative Service
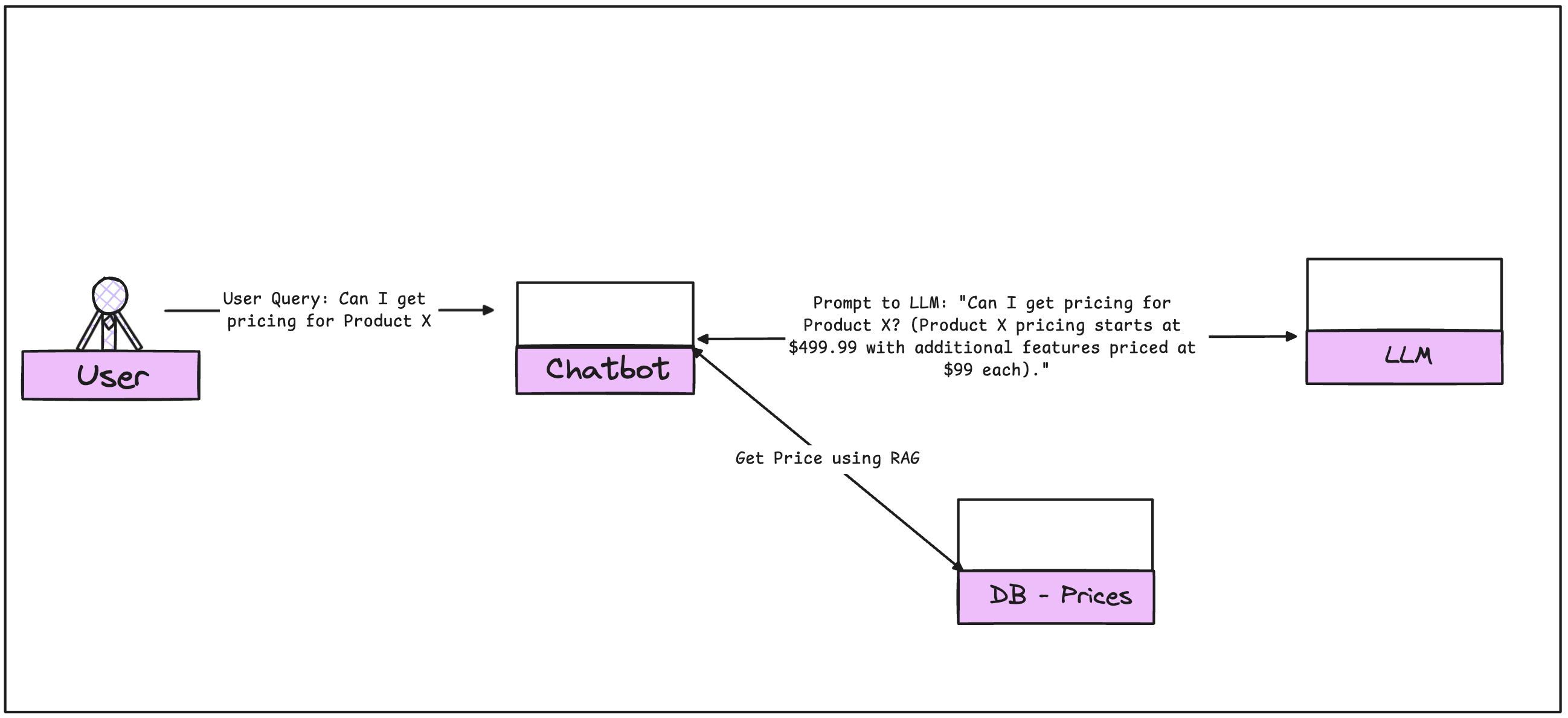
Now comes the fun part—generation. The query, combined with the retrieved context, gets passed to a generative model. This is where you might use OpenAI’s GPT-4 API or Anthropic’s Claude. The prompt sent to the LLM will look something like this:
User query: "What’s the pricing for Product X?" Retrieved context: "Product X pricing starts at $499.99." Augmented prompt: "What’s the pricing for Product X? (Product X pricing starts at $499.99)."
5. Post-Processing & Response Management
Once the LLM generates a response, it goes through post-processing:
Sanitization: Ensure the response isn’t offensive or out of bounds (think moderation APIs like OpenAI’s own or a homegrown profanity filter).
Caching: Common responses should be cached (again, Redis is perfect here). Use LRU (Least Recently Used) caching strategies to ensure stale responses are removed.
Low-Level Design Tip: Use event-driven architecture for tasks like logging or analytics. Tools like Kafka or RabbitMQ let you decouple your services and handle background tasks asynchronously.
Frontend: Designing the Experience
The backend might be the brains, but the frontend is the face. It needs to be slick, fast, and human-friendly. Here’s how to build a UI that feels intuitive and responsive.
1. Real-Time Interaction with WebSockets
For real-time chat experiences, WebSockets are the clear winner over traditional HTTP. With WebSockets, the connection stays open, allowing two-way communication between the frontend and backend.
Socket.IO is the best choice here for Node.js. If you’re working in Python, Django Channels will get the job done. For frameworks like React or Vue, WebSocket integration is straightforward and well-supported.
2. UI/UX Design Patterns
A chatbot is more than just a text box. Here’s what your UI needs to elevate the experience:
Message Bubbles: Keep responses and queries in neat message bubbles. Libraries like Material-UI or Ant Design in React work well for this.
Typing Indicators: Show when the bot is “thinking”—never let the user wonder if the system is down.
History and Context: Display conversation history so the user can easily scroll back through past interactions. This also helps the bot appear more human.
Frontend Best Practice: Use Next.js (for React) or Nuxt.js (for Vue) to ensure fast server-side rendering (SSR) and reduce time-to-interaction. Since chatbots are often deployed on dynamic websites, SSR helps with SEO and initial load times.
3. Managing State and Memory
A chatbot that can’t remember past conversations is like a fish with a three-second memory. Use a state management library like Redux (for React) or Vuex (for Vue) to keep track of multi-turn conversations.
LocalStorage or IndexedDB can handle persistence between sessions.
4. Importance of Feedback Loops
Building a chatbot isn’t a one-time project; it requires continuous improvement, and user feedback loops are at the heart of this. Without real-time user feedback, it's impossible to know when the system is failing or underperforming in the wild. Collecting metrics on user satisfaction (e.g., using quick thumbs-up/down buttons on responses), logging edge cases, and using this data to refine the retrieval and generative processes are essential steps for ensuring long-term success.
Furthermore, for teams aiming to get serious about chatbot performance, A/B testing different retrieval and generation strategies is invaluable. By splitting users into groups and trying different retrieval thresholds, ranking strategies, or prompt formulations, teams can scientifically determine which approach works best for their specific use case.
Data Models and Conversation Memory
When designing a chatbot that handles long, multi-turn conversations, memory management becomes a significant technical hurdle. LLMs have a finite context window, meaning they can only consider a limited number of tokens (words) at a time. For chatbots that need to engage in ongoing conversations (e.g., over several customer service interactions), it’s critical to implement a sliding window memory mechanism. This allows the model to focus on the most recent turns in the conversation while maintaining an overarching context of the interaction.
{
"conversation_id": "abc123",
"user_input": "What is the price of Product X?",
"bot_response": "The price is $499.99."
}
Pro Move: Use NoSQL databases like MongoDB or DynamoDB to store conversation histories. These databases allow for quick, flexible queries when fetching user conversation data across multiple sessions.
For persistent memory across sessions, some teams implement session-based memory, storing conversations as objects in NoSQL databases like MongoDB or DynamoDB. This allows the chatbot to recall key points from past interactions, providing a more human-like experience.
But memory isn’t just about remembering—it's also about forgetting. To prevent chatbots from regurgitating outdated or irrelevant information, systems need to incorporate expiration mechanisms for stored memory, ensuring that the chatbot’s knowledge evolves with the user’s needs and the company's latest updates.
As for document retrieval, version control is key when you’re dealing with frequently updated knowledge bases. One effective approach is tagging document chunks with version metadata so the system can retrieve the most recent information. When a new version of a document is added, the embeddings for older versions can be flagged for archival or de-prioritization in retrieval.
One crucial aspect often overlooked in production systems is ensuring data privacy and compliance with regulations like GDPR or CCPA. When handling user conversations—especially in industries like healthcare or finance—teams must ensure that sensitive information is stored and retrieved in a compliant manner.
This could mean encrypting embeddings and stored conversations, anonymizing user data, and implementing user consent mechanisms that allow users to control how their data is used. For compliance, teams might also implement data retention policies, where conversation histories are purged after a set period.
If there’s one takeaway here: simplicity scales. Stick to the proven tools and methods, design for resilience, and keep optimizing.
————————————————END—OF—EPISODE—1—————————————————
In the next episode,
We will talk more about Hallucinations, Post Prod Journey, Prompt Behaviour and why sometimes AI does not do what you want it to do?
It would also go on touch upon - What’s next after building a ChatBot or an LLM API Wrapper? How does one measure performance on production? What are the right LLM evaluation framework and methods? Is there more to AI than generation? How to build systems that are capable of thinking and making autonomous decisions? (AI Agents).
See you in Episode 2!
Thanks for reading Unengineered! Subscribe for free to receive new posts and support my work.